# 군집 분석
: 측정된 유사성을 통해 데이터를 그룹화 하여 데이터의 숨겨진 패턴을 찾는 방법
: 비지도 학습
# 유사도 측정
-> 거리 기반으로 측정
- 연속형 변수
1) 유클라디안 거리
: 두 점 사이의 거리(가장 짧은 거리)
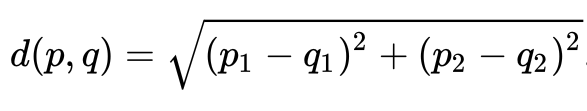

2) 맨하탄 거리
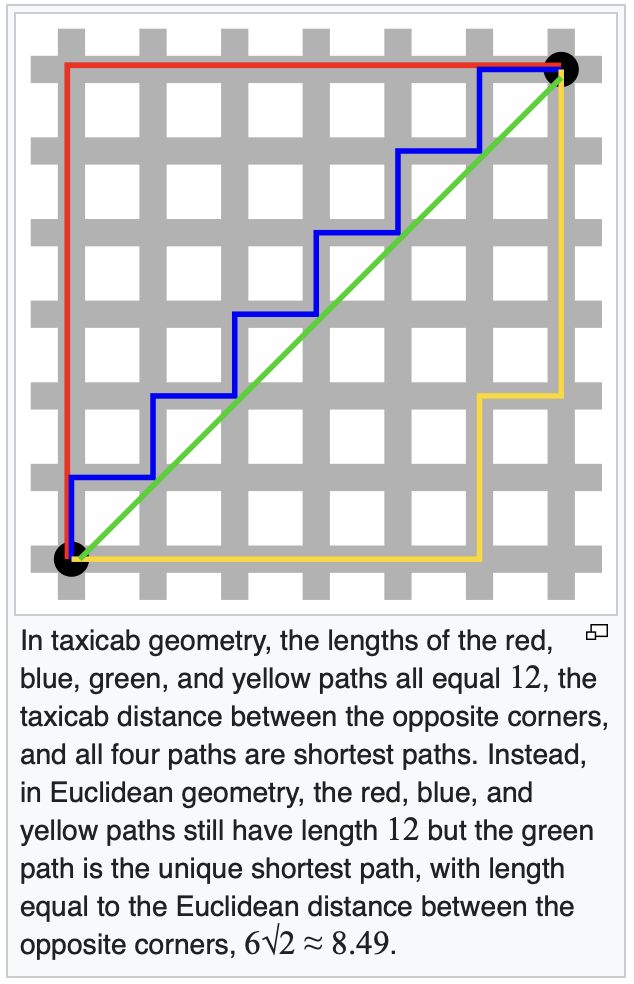
: 격자 구조에서 한 점에서 다른 점까지 이동 시, 수평 or 수직으로만 이동할 수 있는 경우의 거리
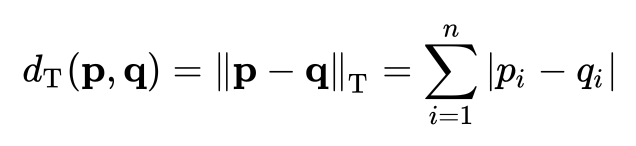
3) 민코우스키 거리
: 유클라디안 거리와 맨해튼 거리를 일반화한 형태
(거리 계산 방식 조절을 위한 매개변수 r을 포함)
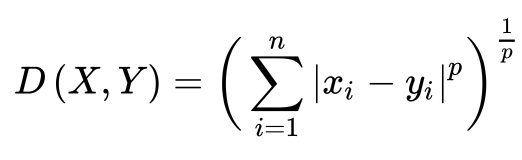
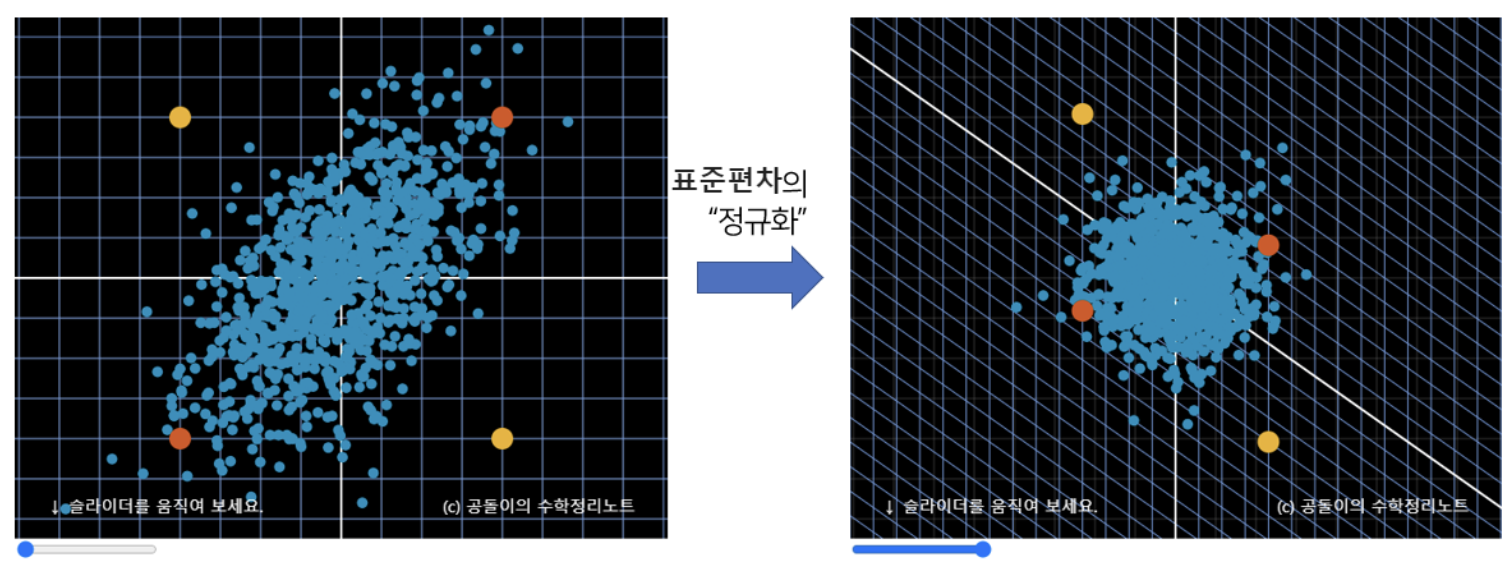
4) 마할라노비스 거리
: 데이터 집합의 통계적 분포(공분산 행렬, Convariance matrix, )를 고려하여 거리를 측정(공분산 행렬의 역행렬, )
: 데이터의 분포에서 표준편차를 조사한 후, 이를 정규화 하여 유클리드 거리를 계산한 것

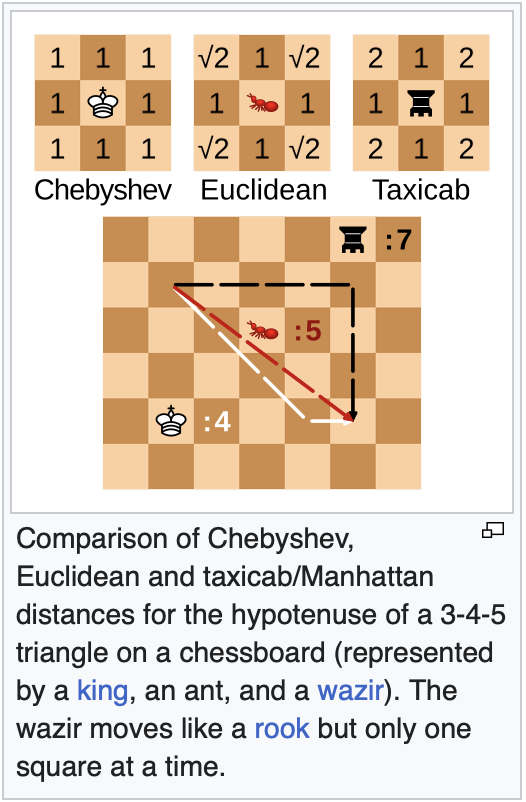
5) 체비셰프 거리
: 두 포인트 사이의 가장 큰 차이를 거리로 측정(가로, 세로, 대각선으로 이동할 수 있음)
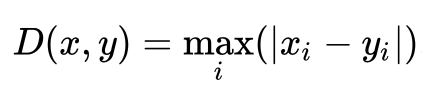

6) 표준화 거리
: 데이터 스케일 차이 제거 후 유클라디안 거리 적용, 분산 적용 O

7) 캔버라 거리
: 차이의 비율을 기반으로 두 점 사이의 거리를 계산
: 두 점 사이의 차이에 대한 절대값을 두점의 합으로 나눈 값의 합
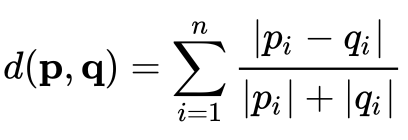
- 범주형 변수
1) 코사인 유사도
: 범주형 데이터를 이진 벡터로 변환 후 코사인 유사도를 사용하여 두 벡터 간의 각도를 측정
: 유사도와 각도는 반비례
: 유사도는 −1에서 1까지의 값을 가지며, −1은 서로 완전히 반대되는 경우, 0은 서로 독립적인 경우, 1은 서로 완전히 같은 경우를 의미
: 거리 = 1 - 유사도
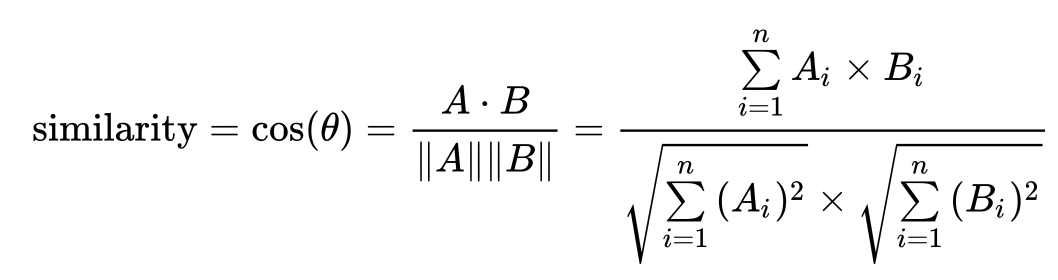
2) 자카드 유사도
: 두 세트간의 교집합 크기를 합집합 크기로 나눈 값
: 0 과 1 사이의 값을 가지며 두 집합이 동일할 때 1, 공통된 원소가 하나도 없을 때 0
: 거리 = 1 - 유사도

# 군집 분석 분류
: 계층적 군집분석 / 비계층적 군집분석
- 계층적 군집 분석(Hierarchical Clustering)
: 데이터들을 점진적으로 병합하거나 나누어 군집을 형성하는 방식
1) 합병적 방법
: 초기에 각각의 데이터를 하나의 군집으로 간주 -> 가까운 데이터부터 순차적으로 병합
: Down - Top 방식

2) 분리형 방법
: 모든 데이터 포인트를 포함하는 하나의 군집에서 시작 -> 군집을 점차 세분화해 나가는 방식
: Top - Down 방식


# 계층적 군집 분석 : 군집 간 유사도 측정 방법

| 최단연결법 | 두 군집 간의 가장 가까운 데이터 쌍의 거리(최단경로) |
| 최장연결법 | 두 군집 내에서 가장 멀리 떨어져 있는 데이터 쌍의 거리(최장경로) |
| 평균연결법 | 두 군집의 모든 데이터들 간의 평균 거리 |
| 와드연결법 | 두 군집을 병합할 때 군집 내의 분산 증가를 최소화하는 방식 (군집 내의 오차 제곱합의 증가가 최소가 되는 방식) |
# 군집 개수 결정 : 덴드로그램
: 계층적 군집 분석의 결과를 시각적으로 표현해줌

- 비계층적 군집 분석()
: 구하고자 하는 군집의 수를 사전에 설정하여 정해진 군집의 수만큼 형성하는 방법
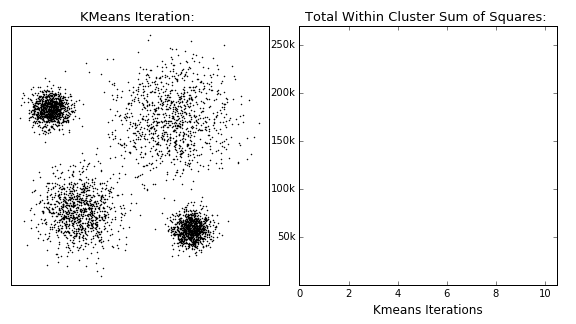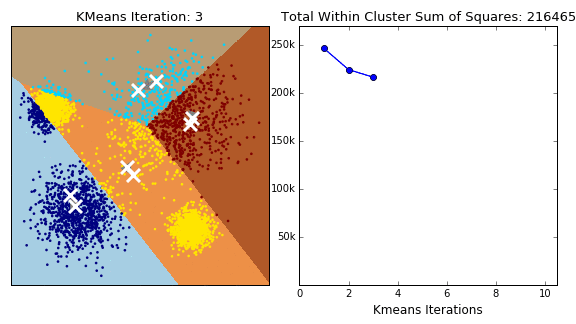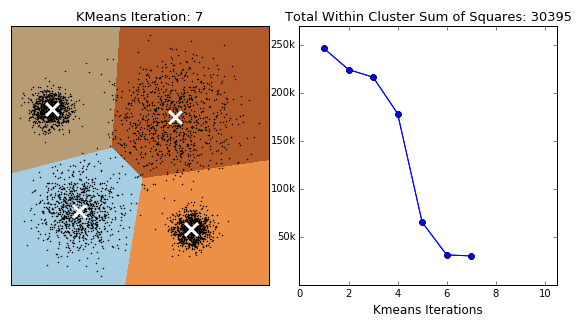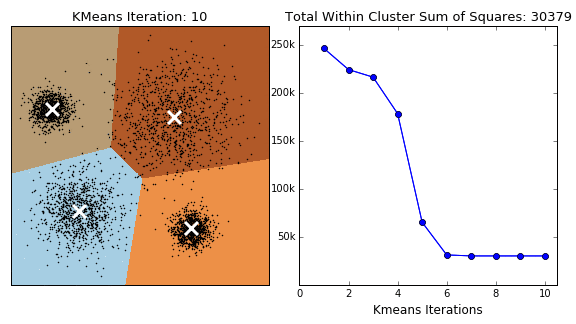
1) K-means 군집 분석
: 군집의 수(k)는 미리 설정, 연속형 변수에서 사용 가능
: 초기중심점은 머리 떨어져 있는 것이 바람직함
: 탐욕적 알고리즘(오차 제곱합을 최소화 하는 방법으로 군집을 형성)
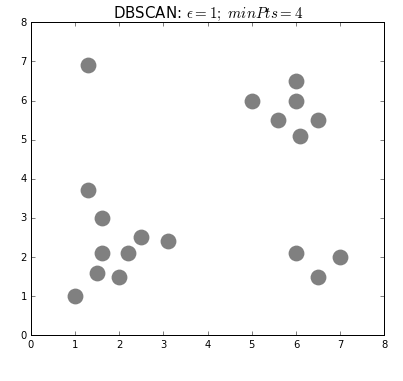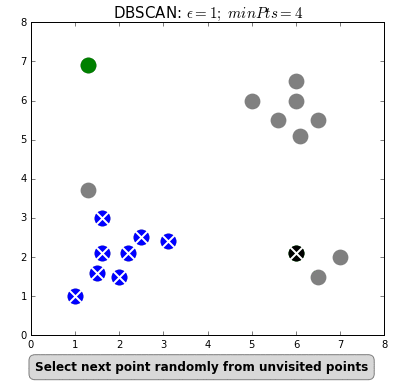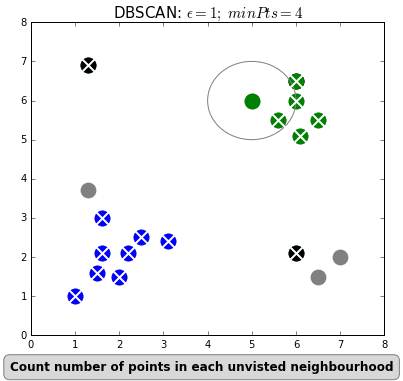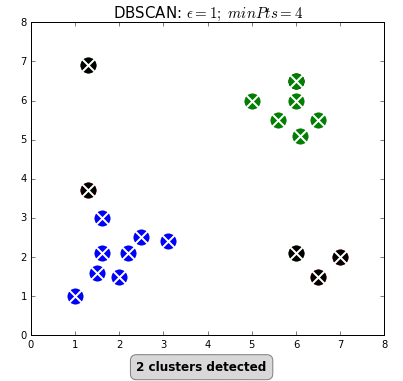
2) DBSCAN
: 밀도 기반 군집분석
: 데이터 분포가 기하학 적이거나, 노이즈가 포함된 데이터 셋에 효과적
: 초기 군집 수를 설정할 필요가 없음
3) 혼합 분포 군집(Mixture Distribution Clustering)
: 혼합분포? 여러 분포를 확률적으로 선형 결합한 분포, 데이터가 여러 개의 서로 다른 확률분포의 혼합으로 구성되어 있다고 가정
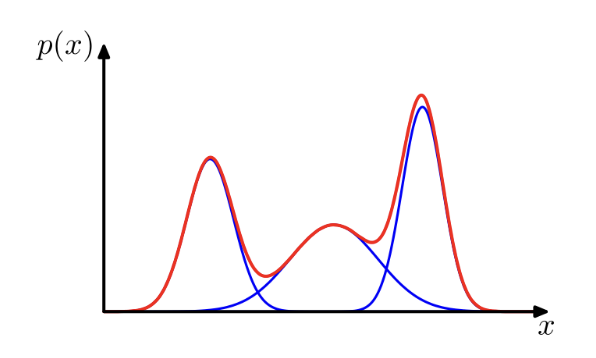
: 모형 기반 군집 방법, 모형을 기반으로 데이터를 군집하는 것
: 각 데이터가 혼합분포 중 어느 모형으로부터 나왓을 확률이 높은지에 따라 군집의 분류가 이뤄짐
: 초기 군집 수를 설정할 필요가 없음
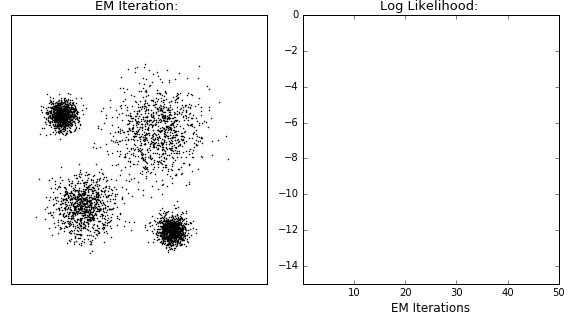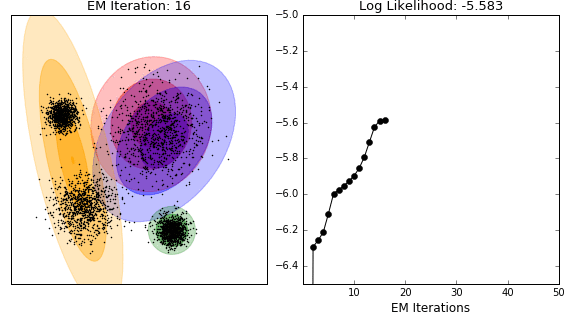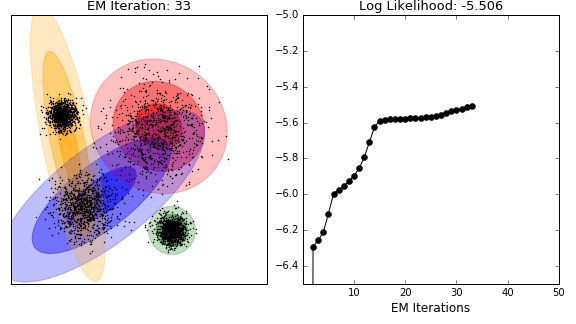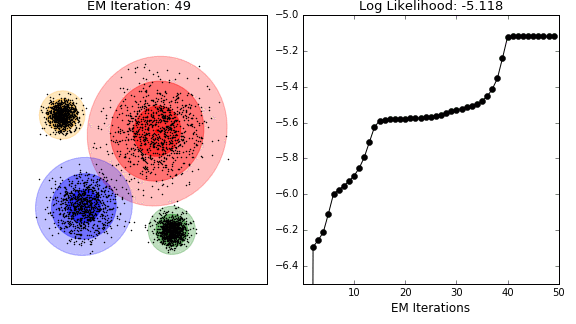
4) EM 알고리즘
: 혼합 모델의 파라미터 추정 시 사용
: E와 M 두가지 단계
: Expectation 단계 - 데이터 포인트가 주어진 분포에 속할 확률을 계산
: Maximization 단계 - 계산된 확률을 통해 모델 파라미터를 업데이트

5) SOM(Self Organizing Map, 자기조직화지도)
: 신경망 기반 군집화
: 입력층(입력벡터를 받는 층)과 경쟁층(2차원 격자로 구성된 층)으로 이루어져 있음
: 고차원 데이터를 저차원에 매핑 -> 데이터의 위치 관계 보존 O, 시각적 이해가 쉬움
: 경쟁학습(승자 독식 구조)
: 단 하나의 전방패스 -> 수행 속도 빠름
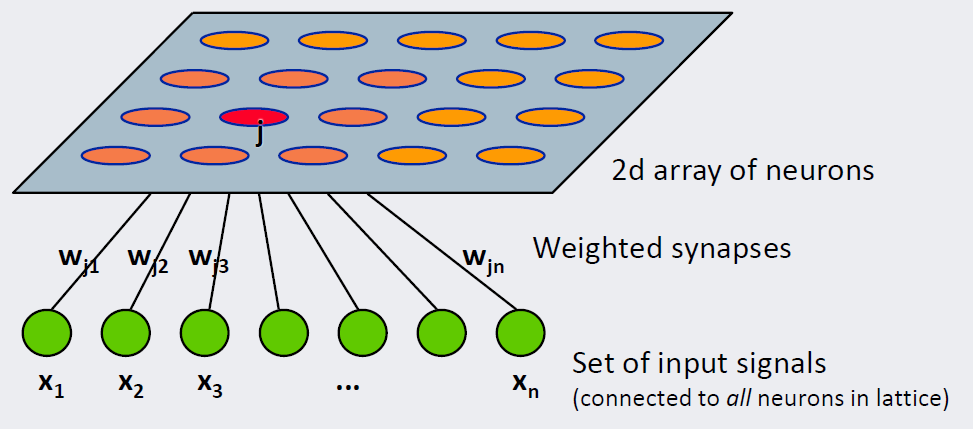
- 초록색 노드(𝑥𝑖)는 𝑛차원 입력벡터의 각 요소
- 주황색 노드(𝑤𝑗)는 2차원 격자
저차원 격자 하나에는 여러 개의 입력벡터들이 속할 수 있음. 여기에 속한 입력벡터들끼리는 서로 위치적인 유사도를 가집니다(=가까운 곳에 있음).
그럼 임의의 입력벡터가 주어졌을 때 2차원상 어떤 격자에 속하는지?
위 그림 기준으로 𝑗번째 격자는 원데이터 공간에 존재하는 𝑛차원 벡터 [𝑤𝑗1,𝑤𝑗2,…,𝑤𝑗𝑛]에 대응
다시 말해 2차원상 격자가 위 그림처럼 25개라면 그에 해당하는 𝑛차원 크기의 격자벡터도 25개 있음
# 군집화 평가: 실루엣 계수
: 군집 내의 데이터들이 다른 군집에 비해 얼마나 잘 분리되어 있는지를 측정
: -1 ~ 1 사이의 값
- 1 : 군집화가 잘 되어있음
- 0 : 군집 간 구분이 불분명함
- -1 : 군집화가 전혀 이루어지지 않음


같은 클러스터에 속한 데이터들과의 평균 거리
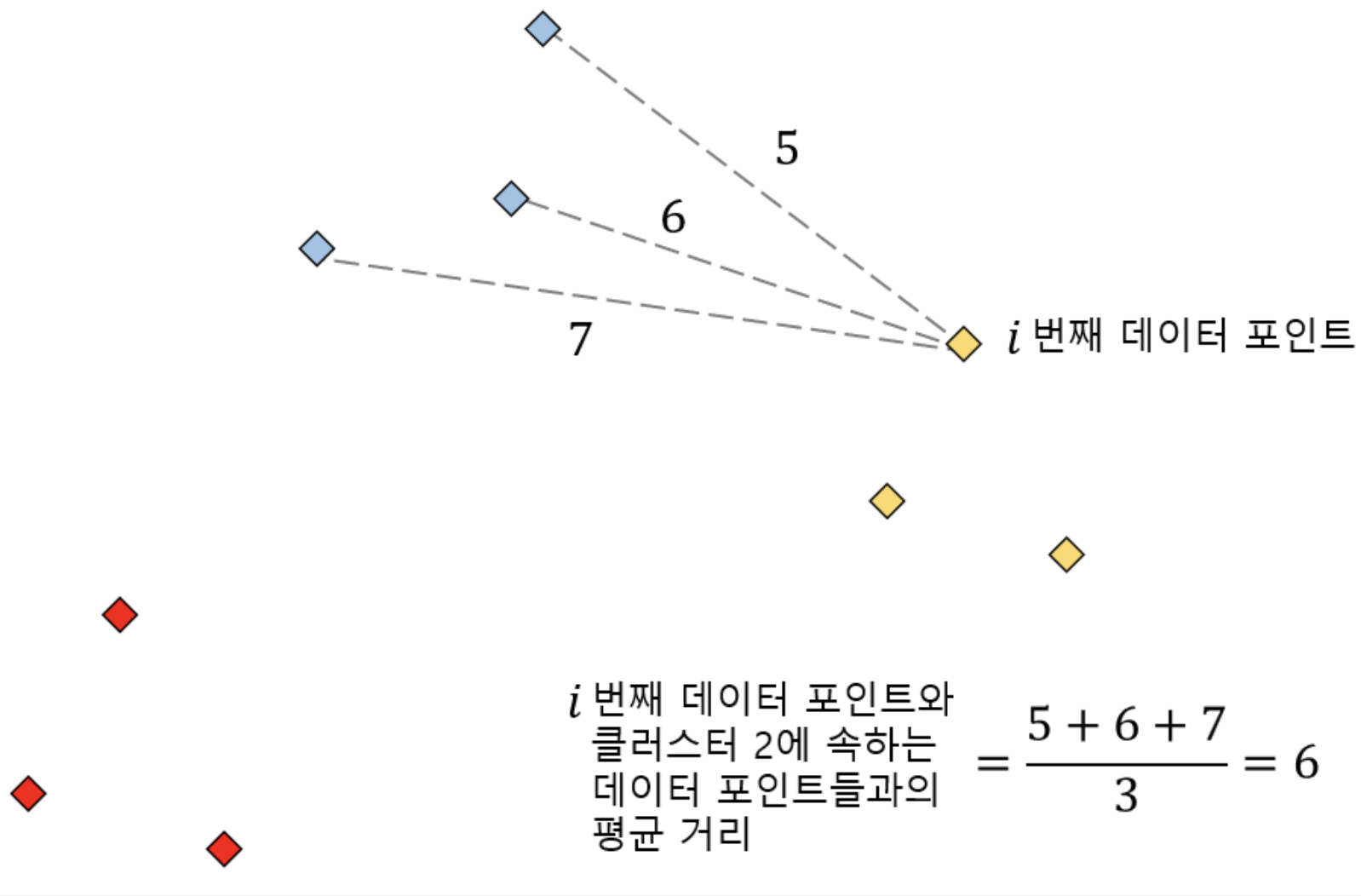
다른 클러스터에 있는 데이터와의 평균 거리
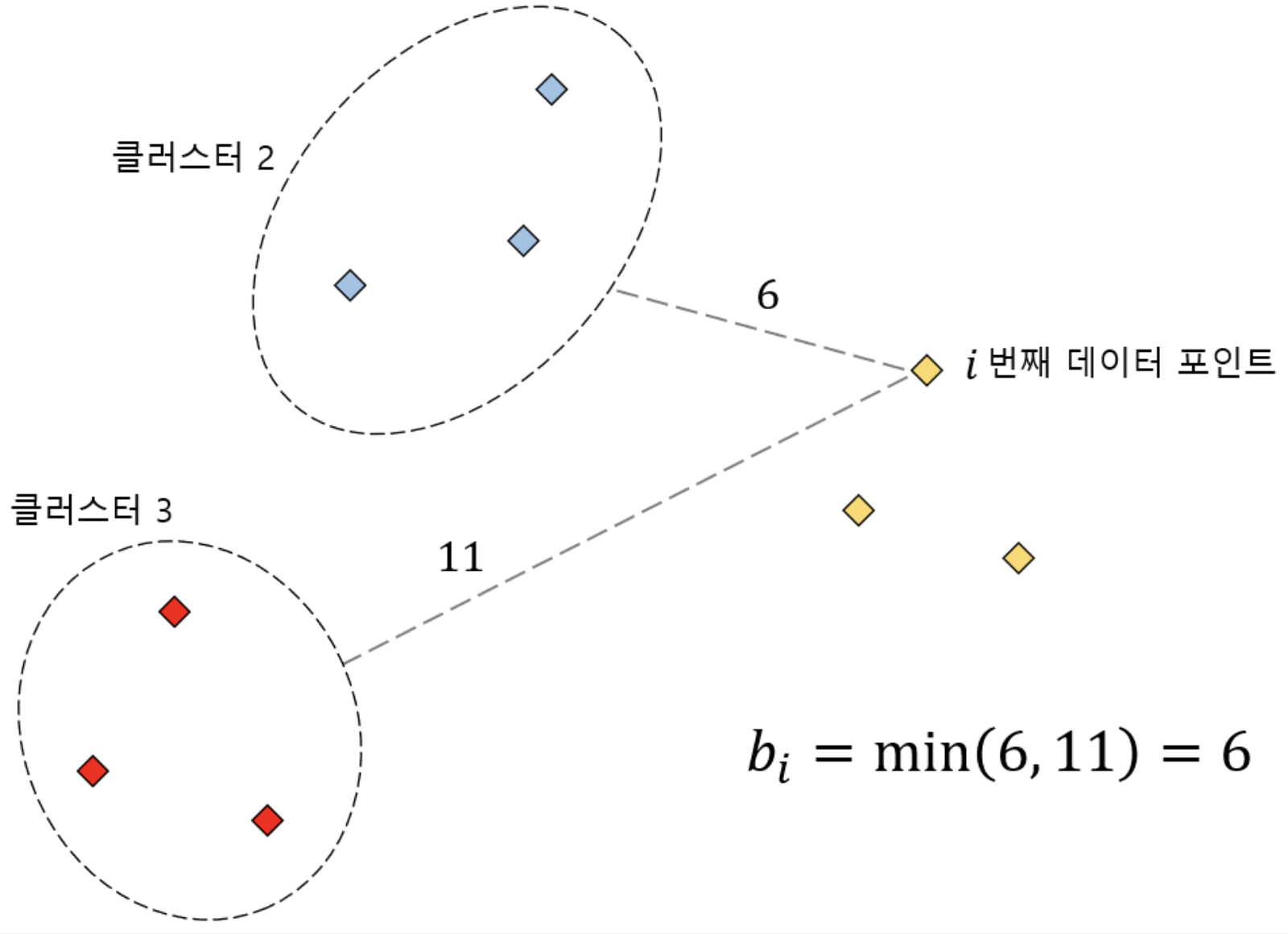
다른 클러스터와의 평균 거리 중 최소 값

b-a를 a와 b의 값 충 최대 값으로 나눔
'자격증 > ADP' 카테고리의 다른 글
| [ADP] 5과목) 1장 시각화 인사이트 프로세스 (5) | 2025.07.27 |
|---|---|
| [ADP] 4과목) 5장 정형 데이터 마이닝 - 6절 연관분석 (2) | 2025.07.27 |
| [ADP] 4과목) 5장 정형 데이터 마이닝 - 4절 인공신경망 분석 (0) | 2025.07.23 |
| [ADP] 4과목) 5장 정형 데이터 마이닝 - 3절 앙상블 분석 (1) | 2025.07.23 |
| [ADP] 1과목) 2장 데이터의 가치와 미래 - 1. 빅데이터의 이해 (0) | 2025.07.23 |